TL;DR
Manticore automatically builds hybrid language models by combining pretrained components (like Transformers and Mamba) instead of training from scratch. We use lightweight “projectors” to align different architectures and learnable “mixture weights” to decide how much each component contributes. The framework leverages MAD tasks as cheap proxies to discover good hybrid designs before applying them to expensive real-world tasks. Results show consistent improvements over individual models, especially on heterogeneous datasets where different architectures have complementary strengths.
Automating Hybrid Design Without Pretraining
The number of possible language model architecture choices is increasing rapidly. Transformers remain the foundation of most state-of-the-art systems, but the ecosystem is diversifying rapidly. Alternatives such as Mamba bring linear-time inference and new capabilities, while recurrent and state-space models are enjoying a renaissance. What’s missing is a clear “winner.” Transformers perform well on many tasks, but not all. They excel at in-context learning and parallel processing but struggle with very long sequences due to quadratic attention costs. Mamba shines in some settings, particularly those requiring efficient long-range modeling, but lags in others where the inductive biases of attention matter. This uneven landscape has naturally led researchers to hybrids: models that combine the strengths of multiple architectures. If Transformers handle in-context learning and Mamba handles long-range dependencies, then perhaps a hybrid can do both. Early demonstrations, like MambaFormer and Jamba, show that the idea works. But building them by hand is costly and fragile. The design space is enormous (which blocks go where? how many of each?) and manual exploration doesn’t scale. Most hybrids need to be trained from scratch because different architectures operate in incompatible feature spaces, and they rarely take advantage of the massive pool of pretrained models that already exist. With Manticore, we wanted to change that. Our framework automatically builds hybrids out of pretrained components. Instead of discarding years of compute and data, we reuse existing models, align their representations with lightweight projectors, and let learnable weights decide how much each model contributes. The result is a practical way to create pretrained hybrids, without incurring the costs that have held hybrids back.

Why Hybrids Are Hard
To understand the need for Manticore, it helps to look more closely at why hybrids have been difficult to build in practice.
The first obstacle is the sheer size of the design space. Once you allow blocks from different architectures to be combined, the number of possible hybrids explodes combinatorially. How many Transformer layers should you use? How often should you alternate them with Mamba blocks? Do you put them at the beginning of the model, at the end, or scatter them throughout? Should you use residual connections between hybrid blocks? Each choice creates new branches in an already vast tree of possibilities. Without a systematic way of navigating this space, most designs come down to either brute force or intuition, both of which are expensive and brittle.
The second obstacle is compatibility. Pretrained models are incredibly valuable (they encode billions of tokens’ worth of learned patterns) but the internal “languages” spoken by their blocks are different. The hidden states of a Transformer and those of a state-space model live in different representational spaces, often with different dimensions. If you try to stitch them together directly, the representations won’t align and they will fail to communicate. A Transformer block expects certain distributional properties in its inputs that a Mamba block’s outputs don’t naturally provide, and vice versa. That means most existing hybrids have had to throw away pretrained weights and start from scratch, treating the problem as pure architecture search rather than component reuse.
Third, there is the cost. Training a large model from scratch is already enormously expensive, often millions of dollars in compute for frontier models, and training multiple hybrids just to see what works is out of reach for most groups. Even when the potential benefits are clear, the barrier has been too high. This is particularly frustrating because the pretrained models we’d want to combine already exist and are publicly available.
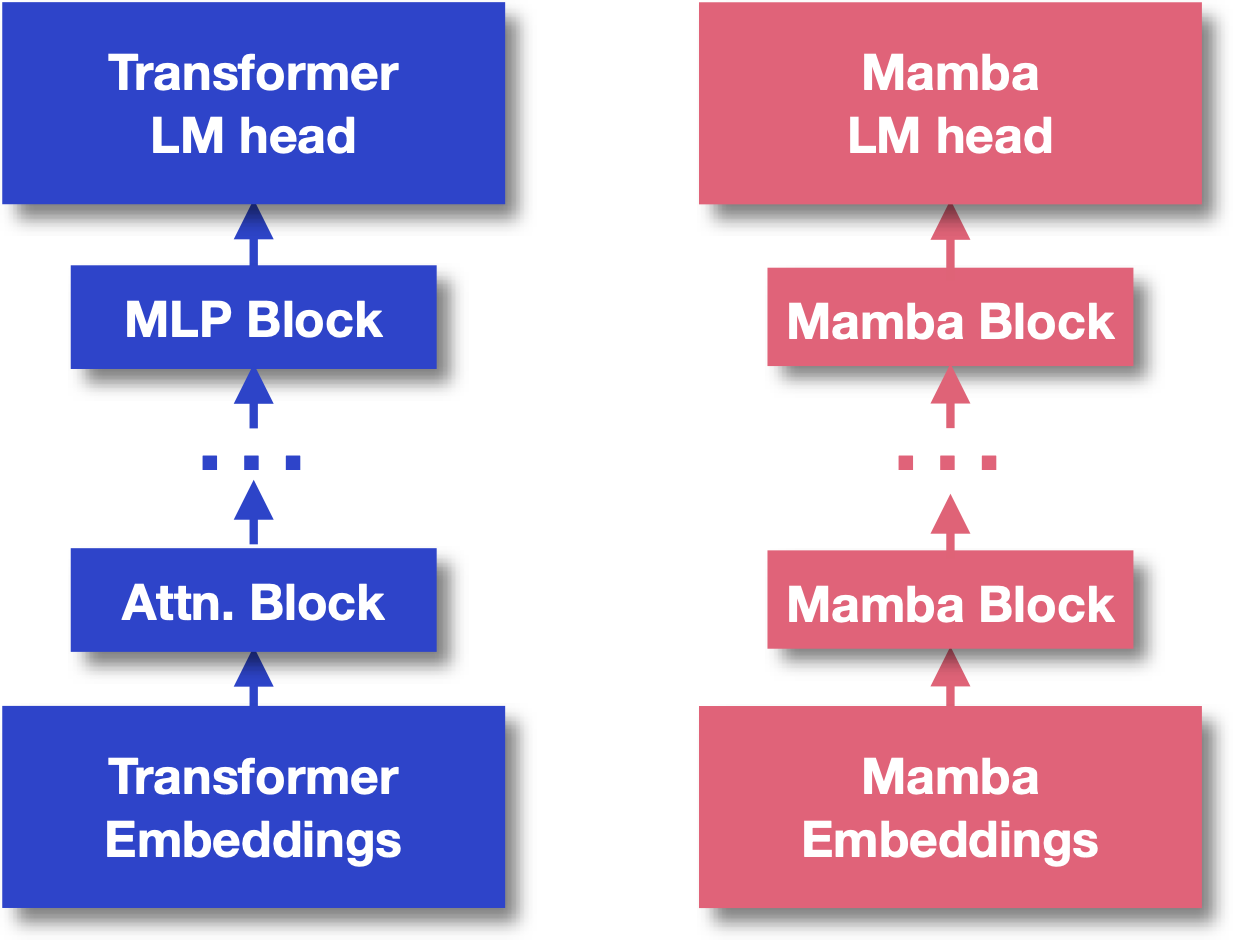
A Different Approach
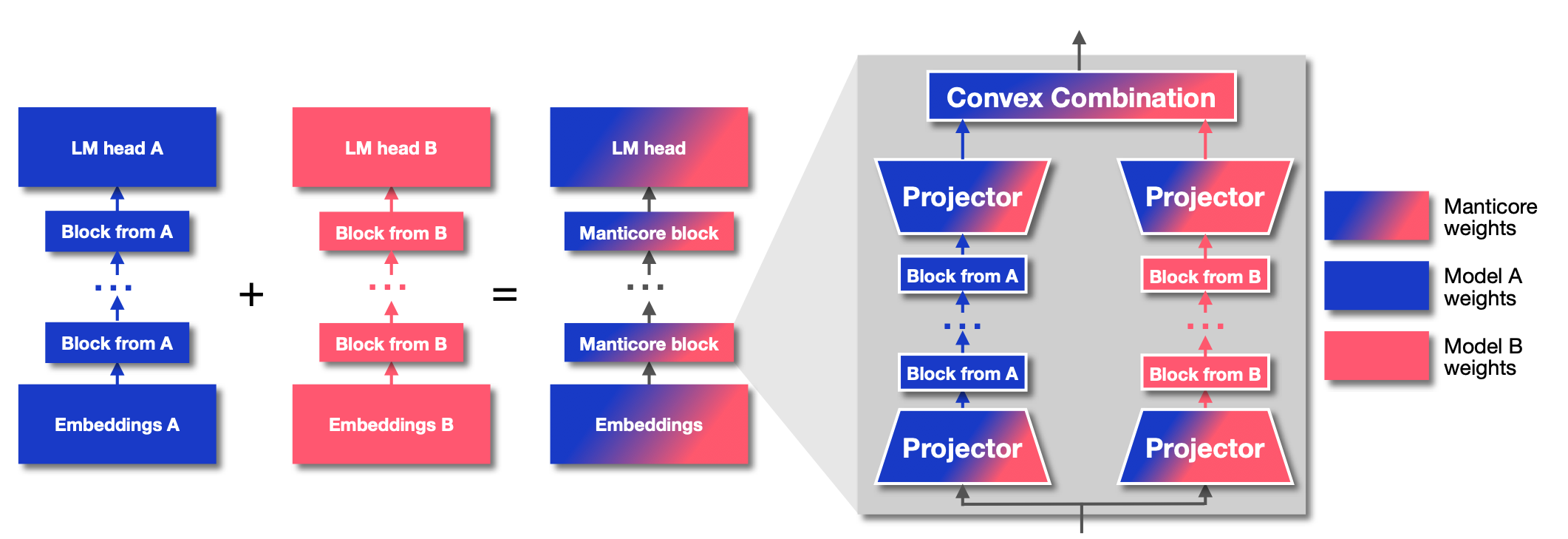
Manticore tackles these challenges head on. It is named after the Persian mythological creature: a human, a lion, and a scorpion combined into something new. Our framework plays the same trick in the model space, mixing pretrained blocks into functional hybrids (we call the pretrained models that we combined “component models”). The key idea is that you don’t need a brand new architecture or a complicated merging procedure. Instead, you add just two ingredients: projectors that make different pretrained models’ features compatible, and weights that decide how to blend them. This is similar in spirit to model merging techniques, but instead of interpolating weights, we’re interpolating forward passes through different models’ blocks.
Projectors. These are small linear layers with gated residuals that translate features from one architecture into a shared space. The gating mechanism is crucial: it allows the projector to learn when to apply the transformation and when to pass features through unchanged. We expected that aligning very different models might require complex transformations and large datasets, perhaps needing multiple layers or nonlinear activations. Instead, we discovered that linear projectors trained on just 100 million tokens of general text were enough. This is surprisingly small, less than 0.1% of what most foundation models see during pretraining. They are lightweight (adding minimal parameters compared to the component models), easy to train (converging in hours rather than weeks), and can be reused for many downstream tasks without retraining. Once you’ve aligned GPT-Neo and Mamba, those projectors work across multiple fine-tuning tasks.
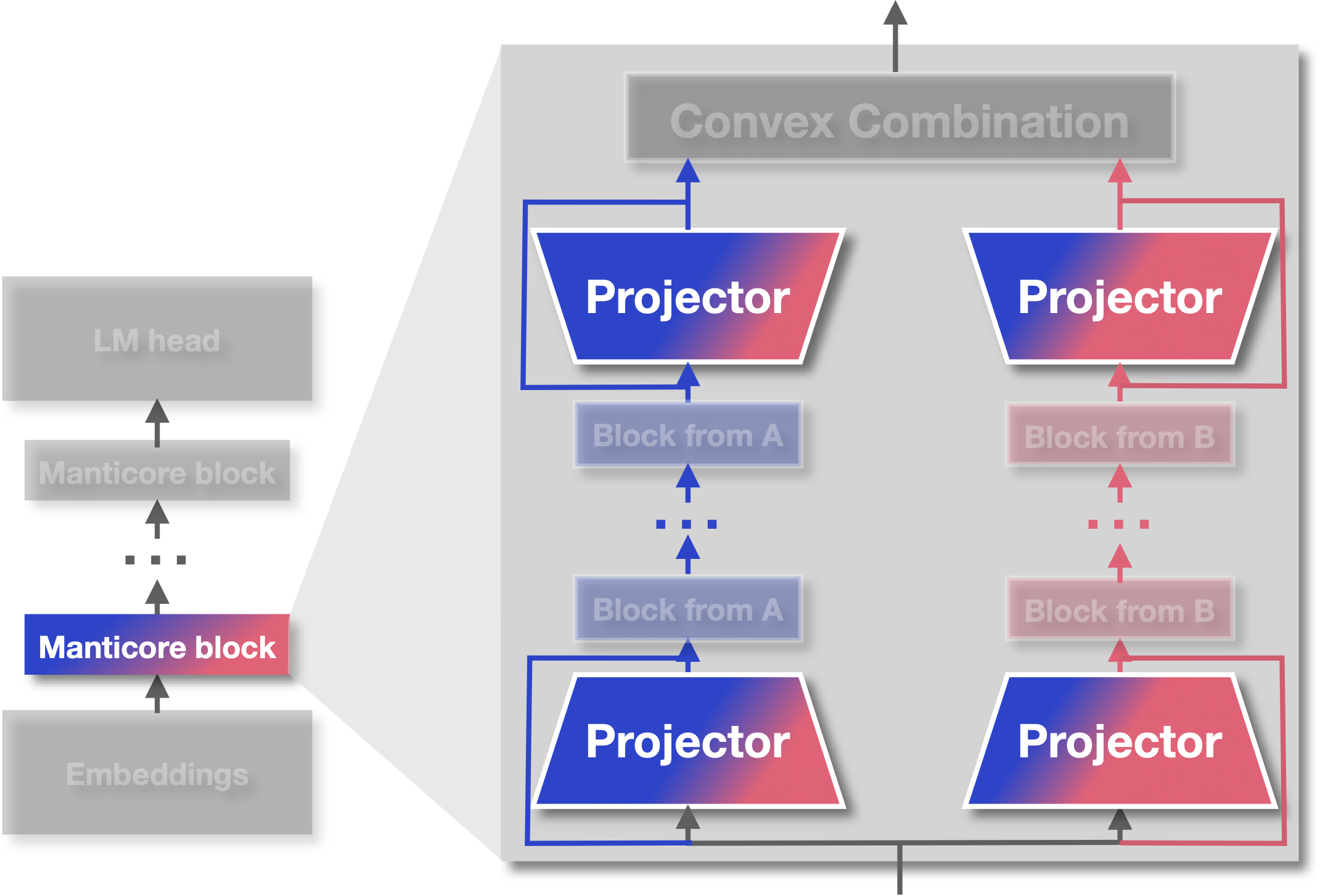
Mixture weights. Once the features are in the same space, we still need to decide how much of each to keep. This is where neural architecture search comes in. Mixture weights, parameterized as a softmax over learnable scalars, blend the projected outputs from different component models. During training, NAS algorithms such as DARTS or GAEA optimize these weights jointly with the task loss. If one architecture is particularly helpful for the task, its weight increases. If it’s not contributing, the weight drops toward zero. The elegant part is that if the weights collapse to a single option (all mass on one component), Manticore reduces exactly to the original component model. That means our search space always contains the starting models and any possible hybrid in between, including manually designed hybrids like MambaFormer (which are just specific configurations of our mixture weights).
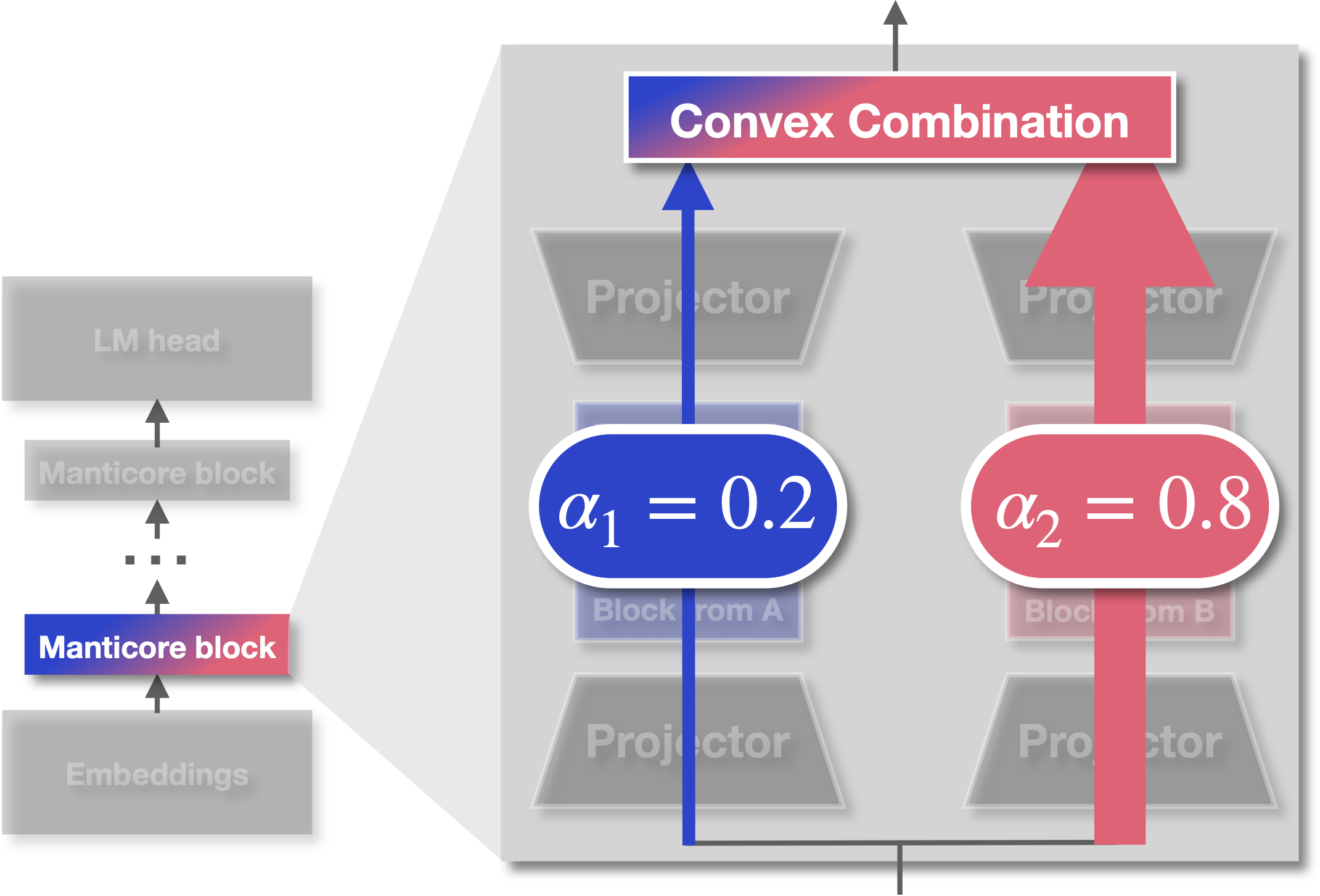
Manticore blocks. Together, projectors and mixture weights form Manticore blocks. By chaining these blocks and dividing each component model’s layers evenly across them, we can connect entire pretrained models (GPT-Neo, Pythia, Mamba) without discarding their weights. What emerges is not a handcrafted curiosity, but a systematic way of constructing hybrids. The framework is general: you can plug in any decoder-only language model that follows the standard embedding → blocks → head structure, and Manticore will figure out how to combine them.
Using MAD as a Guide
Even with these tools, the question remains: which hybrids are worth building? Searching directly on large-scale tasks would defeat the purpose, since it would require massive computation. You’d need to fine-tune many candidate hybrids to see which works best. This is where MAD tasks (Mechanistic Architecture Design) come in. Originally introduced as synthetic “unit tests” for language models, MAD tasks test specific capabilities: in-context recall (can the model retrieve a value associated with a key earlier in context?), selective copying (can it copy specific tokens while ignoring noise?), fuzzy recall (can it group semantically similar keys?), and memorization (can it learn fixed key-value pairs?). These tasks are predictive of scaling behavior on real data. In Manticore, they serve as proxies. We can train smaller hybrids on MAD tasks, observe which mixture weights work well across multiple synthetic benchmarks, and then transfer those insights to larger pretrained hybrids on real-world data. The intuition is that if a hybrid architecture works well on the fundamental capabilities tested by MAD, it’s likely to work well on complex downstream tasks that require those capabilities. In effect, MAD acts like a compass. It doesn’t tell you exactly which path to take, but it points toward regions of the search space that are promising. This lets us “program” hybrids without ever touching the target dataset, saving enormous amounts of compute. For tasks where you can’t afford extensive architecture search (maybe you have limited compute or the dataset is private), MAD provides a way forward.
What the Experiments Showed
We tested Manticore in three scenarios: fine-tuning pretrained hybrids, training hybrids from scratch, and programming hybrids without task-specific data. Across all three, we found that Manticore could discover or match strong hybrids, often with less compute than traditional approaches would require.
Fine-tuning pretrained hybrids. We combined Pythia-410M and Mamba-370M, replacing their embeddings and LM heads with shared components, and added projectors trained on 100M tokens of general text from FineWeb. We created a single Manticore block that mixed blocks from both models, then searched for mixture weights using DARTS. After search, we rewound the component models to their pretrained state and fine-tuned with frozen mixture weights. Fine-tuning these hybrids on Penn Treebank, Alpaca, and ELI5 showed consistent gains over the individual models. On Penn Treebank, the hybrid achieved a loss of 0.86, compared to 0.91 for Pythia and 0.84 for Mamba, landing between the two components but combining their complementary strengths. On Alpaca and ELI5, Manticore outperformed both, achieving 2.18 and 3.93 respectively versus Pythia’s 2.50 and 4.13, with Mamba at 2.30 and 3.94. The improvements were especially clear when the datasets were heterogeneous. On tasks mixing Spanish QA with English instructions, or Chinese QA with Alpaca, Manticore’s ability to dynamically leverage different components for different data slices became apparent. Where Pythia struggled with non-English text and Mamba struggled with instruction-following, the hybrid used both effectively. We also swept the mixture-weight space and found that NAS algorithms (DARTS, GAEA, DASH) reliably discovered the same high-performing regions, suggesting the search landscape is well-behaved.
Training from scratch. To see if the approach works without pretrained weights, we built hybrids from randomly initialized GPT-Neo and Mamba models on MAD tasks and Long Range Arena. On MAD tasks, Manticore matched or approached manually designed hybrids such as MambaFormer and the Striped Hyena architecture. When considering only non-hybrid component architectures, Manticore outperformed the non-hybrid GPT-Neo and Mamba configurations. On the Long Range Arena benchmark, Manticore improved over its component models on 4 of 5 tasks. On ListOps, it achieved 38.7% accuracy versus 37.9% for GPT-Neo and 20.7% for Mamba. On Pathfinder, it hit 91.5% versus 89.4% and 85.8%. The one exception was IMDb, where Mamba (87.7%) substantially outperformed both GPT-Neo (59.6%) and Manticore (72.4%). In this case, our search procedure didn’t fully recover the best single component, suggesting room for improvement in the NAS algorithm. On Pathfinder-X, which required sequence lengths beyond GPT-Neo’s 2048-token limit, Manticore achieved 75.5% by automatically setting GPT-Neo’s mixture weight to zero and reducing to pure Mamba. This demonstrates a key feature: Manticore gracefully handles incompatible components by down-weighting them when necessary.
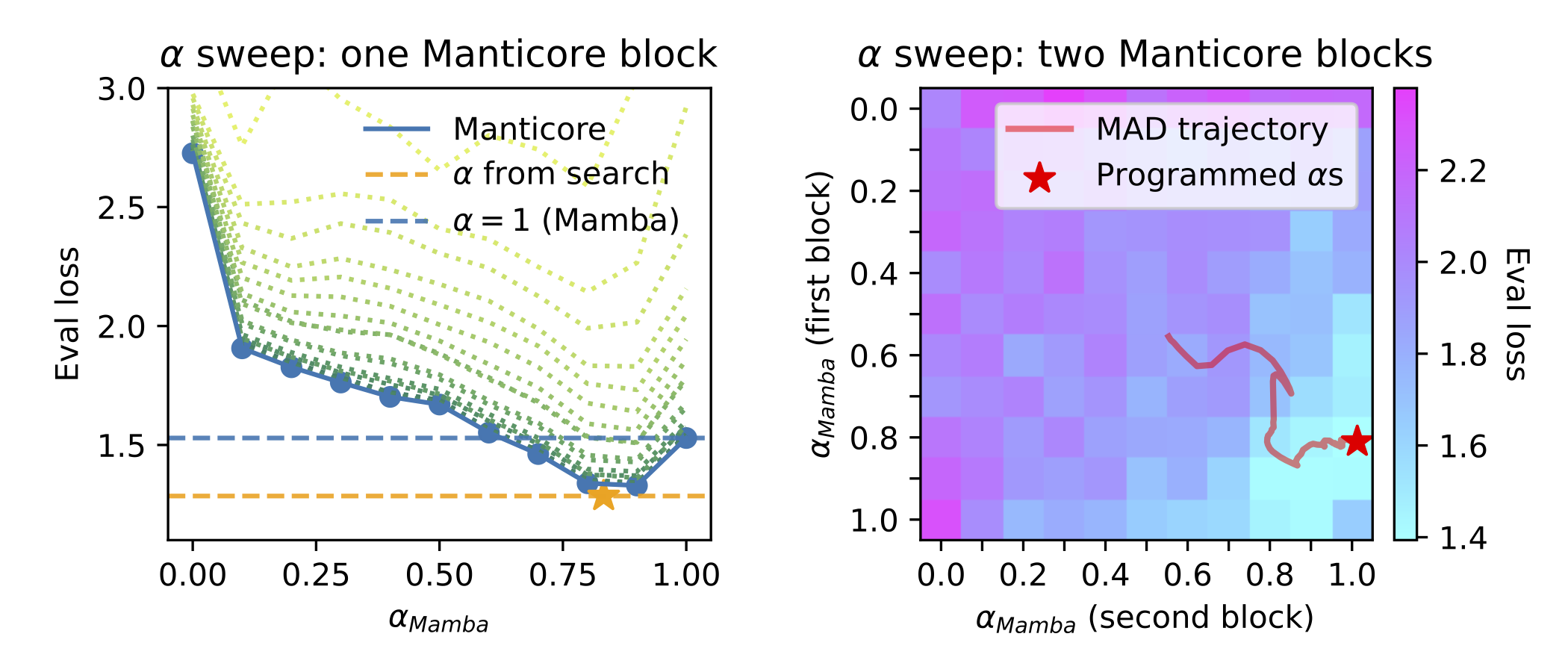
Programming without task data. Finally, we explored whether hybrids could be set up without touching the target task. Sometimes this was as simple as using metadata. If a task required long contexts beyond GPT-Neo’s capacity, we could drop it from the mixture entirely by setting its weight to zero, a form of “programming” based on known architectural constraints. More interestingly, we trained smaller hybrids on MAD tasks, averaged their mixture weights across the synthetic benchmarks, and applied those to pretrained hybrids on Penn Treebank completions. This is the “programming” workflow: search on cheap proxy tasks, transfer to expensive real tasks. On PTB completions (a synthetic dataset we created by prompting GPT-Neo and Mamba with PTB sentences), these MAD-predicted weights landed in the same high-performing region found by full search. The resulting hybrid achieved a loss within a few hundredths of the best discovered by search, and when we visualized the loss landscape by sweeping mixture weights, the MAD trajectory (showing how weights evolved during MAD training) tracked the gradient of the PTB landscape despite being trained on completely different data. This suggests that MAD tasks capture something fundamental about how different architectures complement each other, at least for tasks close to the pretraining distribution. The technique worked less well for tasks far from pretraining (e.g., non-English datasets), where the loss landscapes became less correlated.
Tradeoffs
Manticore is not free. At inference, you need to run each component model, which increases cost compared to using just one. For a hybrid of two ~400M-parameter models, inference costs roughly 2× the FLOPs of a single model. The projectors add negligible overhead, on the order of <1% of total FLOPs, so the cost scales linearly with the number of components. This is still far cheaper than pretraining hybrids from scratch, which would require hundreds of billions of tokens and weeks of compute on large clusters. For many applications, the tradeoff is worth it: you avoid enormous pretraining costs while gaining flexibility to explore new combinations. If inference cost is paramount, you can discretize the mixture weights after search (setting them to one-hot vectors) and deploy only the selected components, though this can reduce performance slightly. Another tradeoff is search. While Manticore works with off-the-shelf NAS algorithms like DARTS, better hybrid-specific search methods could further improve results. We found that DARTS occasionally got stuck in local optima (as on IMDb), and that alternating updates between architecture and model parameters helped in some settings but not others. We see this as an opportunity for future work, developing NAS algorithms tailored to the structure of hybrid language models, not a limitation of the framework. Finally, there’s the question of when hybrids help. Our results suggest they’re most useful when component models have complementary strengths, particularly on heterogeneous datasets. On homogeneous tasks where one architecture dominates, Manticore tends to recover that architecture, which is the right behavior but doesn’t provide gains.
The Bigger Picture
The field no longer revolves around a single architecture. Transformers remain dominant, but recurrent and state-space models are advancing quickly, and more are likely to follow. New architectures like Griffin (combining recurrence and local attention) and Striped Hyena (mixing convolutions and attention) are appearing regularly. Instead of waiting for one to replace the others, Manticore suggests a different path: embrace the diversity. By reusing pretrained models, we preserve the massive investments already made, both the compute spent on pretraining and the knowledge encoded in those models. By automatically searching over mixtures, we can explore new designs without human guesswork or exhaustive enumeration. By leaning on MAD tasks, we can anticipate which hybrids will succeed even before we see the target data. Hybrids have long promised a “best of all worlds” approach, but cost and complexity held them back. With Manticore, we hope to make hybrids practical tools for the community, not just interesting experiments. The framework is open and extensible: new component models can be added as they’re released, new search algorithms can be plugged in, and new proxy tasks beyond MAD can guide the process. We’re excited to see where the community takes this.
If you arrived at this page by scanning our QR code at COLM, and you stuck with it until the end, here are two of our finest cookies for your browser caching pleasure. 🍪🍪 As always, if you’re interested in reading more about Manticore, please check out our paper!
- Paper: Pretrained Hybrids with MAD Skills
- Thread: X/Twitter link